刚刚,Claude Opus 4.8来了!两个史上首次改写历史
刚刚,Claude Opus 4.8来了!两个史上首次改写历史Opus 4.7发布刚43天,Opus 4.8就来了!编程实力暴增,全面霸榜。Claude Code一口气放出上百个agent并行干活,一个人11天就能重写75万行代码、99.8%测试通过。更狠的Claude Mythos,几周后就来。
来自主题: AI资讯
9075 点击 2026-05-29 09:00
 搜索
搜索
Opus 4.7发布刚43天,Opus 4.8就来了!编程实力暴增,全面霸榜。Claude Code一口气放出上百个agent并行干活,一个人11天就能重写75万行代码、99.8%测试通过。更狠的Claude Mythos,几周后就来。

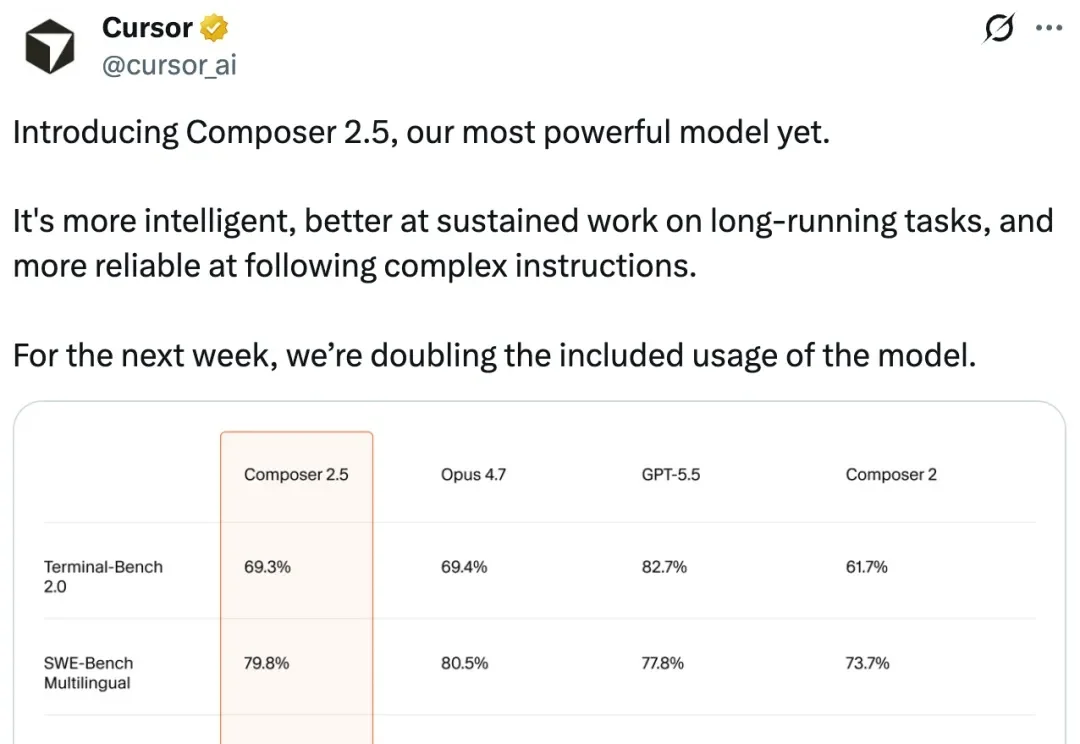
超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

几乎同一天,Anthropic三大超级AI提前曝光!Claude Opus 4.8突袭谷歌后台,Sonnet 4.8跳级4.7。曾经叫嚣着「太危险不公开」的Mythos 1,也现身了。
「以 1/10 的成本,性能几乎追平 Claude Opus 4.7 这个级别的模型。」

上次给大家写了《Codex教程》之后,评论区里陆陆续续冒出来好多问题。问的最多的,是土区订阅 ChatGPT Plus 的事。既然是已经存在的定价差异,还有那么多人不知道,那就写,写清楚,手把手教到会为止。
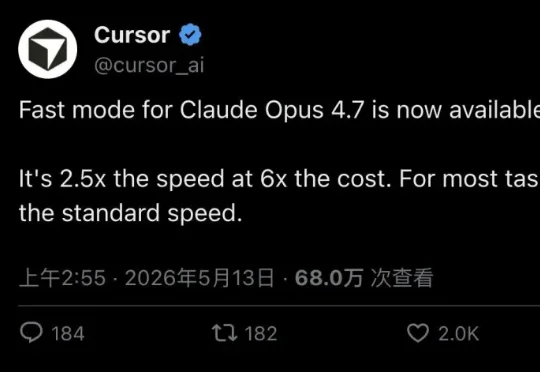
Cursor 正式接入 Claude Opus 4.7 Fast mode——同一个旗舰模型,拆出两个速度档。快 2.5 倍,贵 6 倍,输出价每百万 token 150 美元。最离谱的是,Cursor 官方在发布当天就建议:多数任务请用标准速度。
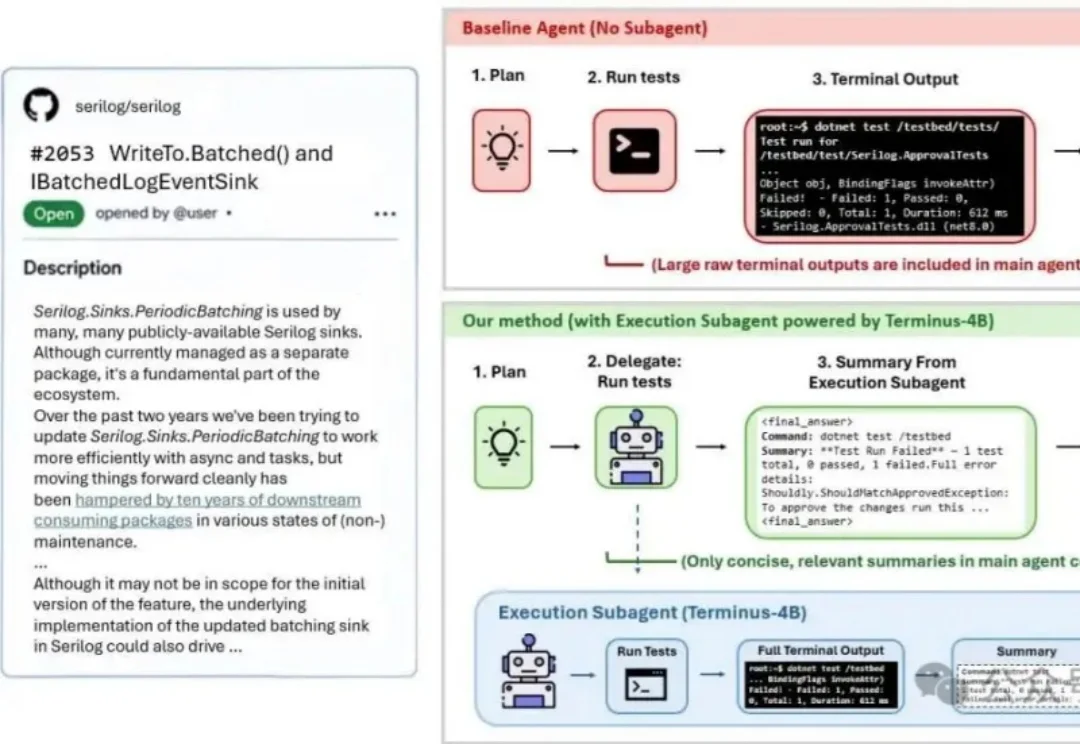
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?

SWE-Bench上能拿72%的模型,换张考卷直接归零!Meta联合斯坦福、哈佛放出ProgramBench,200个项目从零手写,9大顶级模型完整通过率0%。最强的Claude Opus 4.7平均通过率也才51.2%。更离谱的是一联网,就有模型在36%的任务里跑去GitHub扒源码。

Grok 4.3 是 xAI 一次务实升级:更便宜、更快、更像能干活的助手。但它在硬推理、稳定性和可信度上,仍落后 GPT-5.5 与 Claude Opus 4.7。
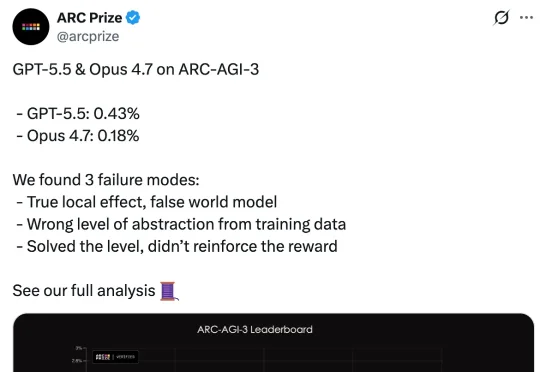
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。